Prompt Injection Has Left the Chatbot
What ServiceNow's AI agent incidents reveal about enterprise workflow integrity.

Prompt injection did not suddenly become dangerous.
We connected it to systems that matter.
For years, prompt injection was treated as a curiosity: a way to make a chatbot ignore rules, leak instructions, or say something awkward. Interesting for demos. Annoying in production. Easy to dismiss as a model behavior problem.
That framing is obsolete.
The recent reporting around ServiceNow AI agent vulnerabilities should make the shift clear. This is not just about a model getting confused. It is about natural-language systems being embedded into trusted enterprise workflows without a new security model around them.
Prompt injection is no longer only a model issue.
It is a workflow integrity problem.
Why prompt injection still works
Large language models do not reliably distinguish instructions from data.
That is the core issue.
Prompt injection hides instructions inside content that appears inert to humans: ticket descriptions, comments, emails, knowledge articles, synced web pages, or documents. The attacker does not need direct access to the model. They only need to get malicious text into something the model will read.
As long as AI systems can:
- Ingest untrusted text
- Interpret it autonomously
- Take real actions through tools
prompt injection remains viable.
ServiceNow is important because it shows what happens when all three conditions exist inside enterprise workflows.
From language confusion to operational impact
Recent disclosures and reporting indicated that AI agents in enterprise workflow environments could, under certain configurations, be manipulated into actions such as impersonation, privileged workflow invocation, delegation to other agents, record modification, or data exposure.
Those are not classic software exploits.
No buffer overflow. No malformed packet. No exotic memory trick.
The attack surface is text.
Once an AI agent is trusted to act, every piece of text it reads becomes a potential control input.
That is the part many teams are still missing.
The exploit chain
The chain is simple:
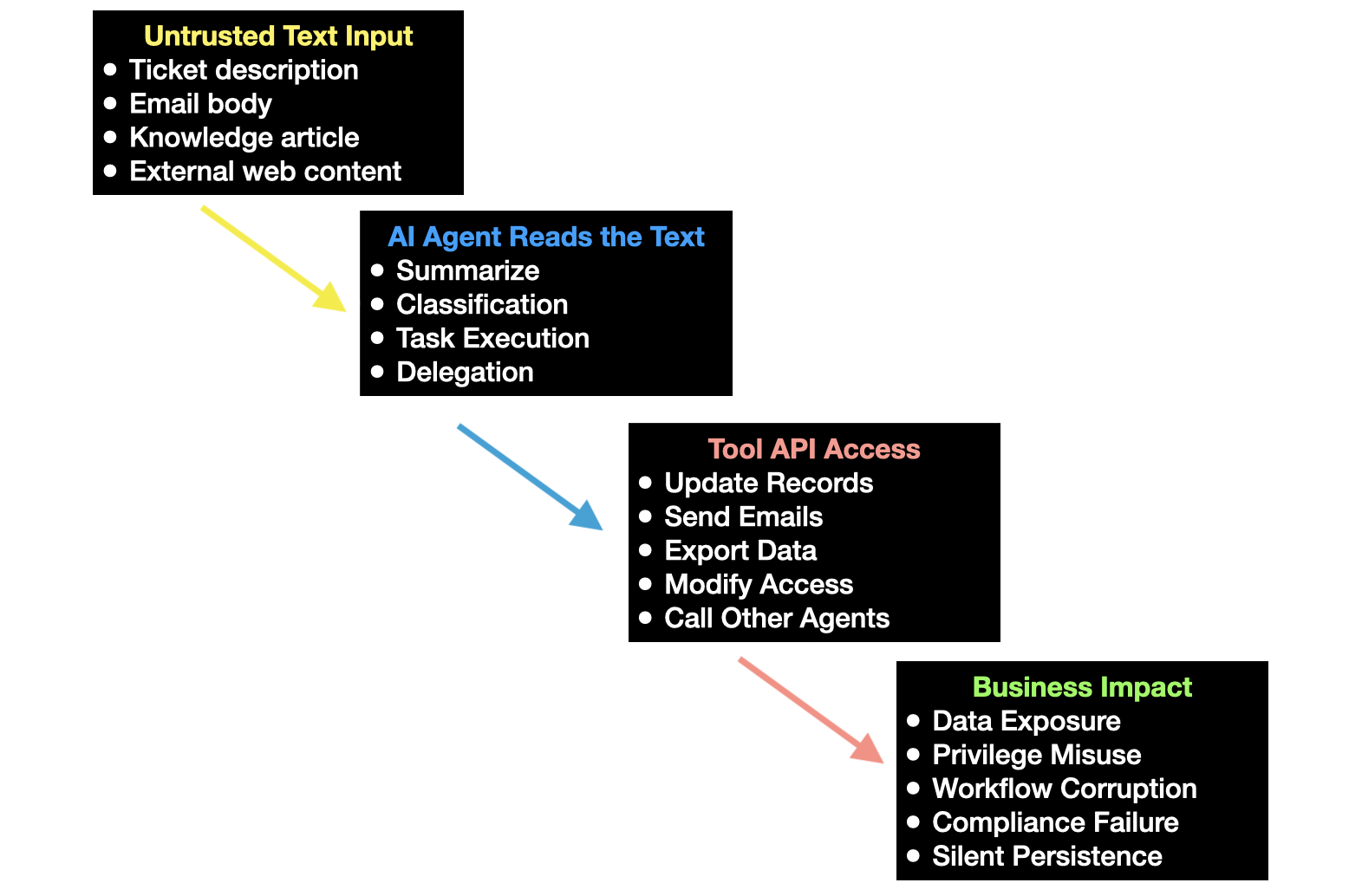
- Attacker places malicious instructions in content the agent will read.
- Agent retrieves or processes that content.
- Agent treats the injected language as relevant instruction.
- Agent selects a tool or workflow.
- Action executes with the agent’s authority.
- The organization discovers the issue after the workflow has already moved.
This is why agent design cannot rely on “the model should know better.”
The system has to assume the model may be confused and still prevent high-impact actions.
The confused deputy problem is back
One of the most concerning patterns is second-order prompt injection.
A lower-privilege agent reads malicious text. It asks a higher-privilege agent for help. The higher-privilege agent executes the harmful action because it believes it is assisting a legitimate workflow.
That is the old confused-deputy problem in a new interface.
Only now the confusion is expressed in natural language, and the deputy may be an AI agent with access to business systems.
From a defender’s perspective, this looks less like a prompt attack and more like lateral movement inside automation.
This is not just a ServiceNow problem
ServiceNow is not unique.
It is early.
Any platform that embeds AI agents into ticketing, CRM, identity workflows, DevOps, knowledge management, internal copilots, or business automation inherits the same risk shape.
The moment an AI agent can do something, not just answer something, text becomes executable input.
That does not mean agents are unusable.
It means they need to be treated as privileged software components, not chat windows with ambition.
What security teams should change
Better prompts are not enough.
The organizations that avoid serious incidents will make structural changes:
- remove ambient authority instead of letting agents inherit broad permissions
- segment agents by impact and allowed delegation paths
- require human approval for irreversible actions
- treat text fields, comments, tickets, and synced content as attack surfaces
- instrument agents like production services
- log prompts, retrieved context, tool calls, identity context, and delegation paths
- alert on unusual tool usage or cross-agent behavior
- design for containment when prompt injection succeeds
That last point matters.
Assume prompt injection cannot be fully prevented. Build systems so that when it happens, damage is limited, visible, and recoverable.
The takeaway
When language controls software, language becomes an attack vector.
That is the new baseline.
The question for every organization is whether it is still modeling AI agents as chatbots, or finally treating them as privileged workflow components.
The answer will decide the blast radius.
Sources and Further Reading
- How Prompt Injection Attacks Actually Work
- AI Vulnerability in ServiceNow Raises Concerns for Remote Workforce Security - Dark Reading
- ServiceNow AI Agents Can Be Tricked Into Harmful Actions - The Hacker News
- ServiceNow AI Agents Can Be Tricked Into Harmful Actions - PointGuard AI
- Moltbook - Simon Willison
- OWASP Prompt Injection

